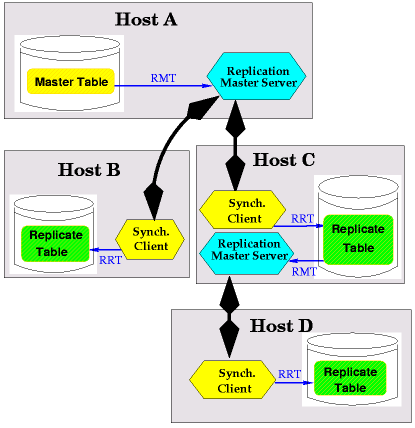
Figure 2-1: An example of a Replication World
If you are new to Empress Replication, after reading this
chapter, you may try the [Quick Start Tutorial]
just to perform a basic replication.
2.2. What is Empress Replication
Empress Replication is a process of creating a set of database tables
as replicates (copies) of a single master
table and their synchronization to a current state of the master table.
Typically, the set of tables lives in separate databases in separate locations.
Collectively, master table and replicate tables are called Replication
World ([Figure 2.1]).
Figure 2-1: An example of a Replication World
A Master Table is an update-able database table that serves as a source of data in a Replication World. A Replicate Table is a read-only database table that gets a copy of data that is updated in a Master Table.
In a Replication World, all data updates are made to a Master Table and are later propagated to Replicate Tables. In [Figure 2.1] data from a Host A have to be propagated to Hosts B, C and D. A propagation of data is done by means of a synchronization. In the process of copying data during synchronization, the origin of data is called Replication Master Table (or RMT) and the copy is called Replication Replicate Table (or RRT).
Note that a table in a Replication World, in its nature, can be a Master or a Replicate Table, but can play two different roles during a synchronization process: it can act as a Replication Master Table (RMT) or as a Replication Replicate Table (RRT). For example, the Replicate Table in the host C in [Figure 2.1] acts as the RRT during the synchronization requested from the Host C, but acts as the RMT for the synchronization requested from the Host D.
Replication Synchronization is a process of updating an RRT with a changed data of its RMT since the last successful synchronization. Synchronization request is made by a Synchronization Client (Empress Replication Synchronization Utility - emprepsync). Synchronization Client attempts to connect to an Empress Replication Master Server, which provides replication (i.e. synchronization) services to its clients. Server listens to synchronization requests from its clients and provides a copy of data from an RMT. In [Figure 2.1] two Replication Master Servers propagate data to all the Hosts: the Server in the Host A and the Server in the Host C.
A synchronization request can be made manually, or can be automated. For this operation, an RRT side does not have to be always connected to a host machine running Replication Master Server, but only for a duration of synchronization. Empress replication is an asynchronous replication. Hence, there will always be a lag between RMT and its RRT defined by a frequency of synchronization.
When created, a Replicate Table inherits a table structure of its RMT. In general, all Replicate Tables in a Replication World have the same structure as a Master Table. Furthermore, since a Master Table is the only update-able table in a Replication World, all data comes from the same source. For the sake of performance, creating a Replicate Table provides an option for the initial loading of the RMT data, before the indices are created.
Since Empress Replication propagates data changes, it is Data-based Replication (instead of being Log-based Replication, when the commands are re-executed on the replicates).
Subset Replication is a special feature of Empress Replication.
A replicate table is normally created as a replica of an entire RMT,
but it may also be created as a subset of an RMT by
specifying a conditional expression (using an SQL WHERE Clause).
Subset Replication duplicates rows from an RMT that satisfy
the predetermined condition.
2.3. Why to use Empress Replication
There are many benefits of using Empress Replication. Some of the
important ones are: